Des captcha à la traduction, la collaboration massive comme business model
Les petites contributions associées massivement font les grands ruisseaux…
Tous ceux qui utilisent le Web ont un ou l’autre jour utilisé cette petite boîte remplie de mots bizarres qu’il faut scrupuleusement sous peine de ne pouvoir accéder au service demandé (généralement une inscription ou la validation d’envoi d’email de contact). Les CAPTCHA (qui est l’acronyme de « Completely Automated Public Turing test to tell Computers and Humans Apart ») ont pour but de différencier si l’utilisateur du service est bien un humain, ou s’il s’agit d’un traitement automatisé par un robot (pour spammer par exemple).
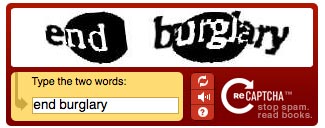
Le principe d’utilisation est fort simple : l’utilisateur doit saisir un ou plusieurs mots ou chiffres qui sont déformés, si la saisie est reconnue alors la requête est validée et l’utilisateur accèdera au service…
La collaboration massive au secours de la numérisation des livres
Luis von Ahn responsable de la numérisation de livres dans 70 universités et à l’origine du modèle CAPTCHA a posé le calcul suivant :
- La saisie d’un captcha par un utilisateur prend 10 secondes
- 200 millions de captcha sont saisis chaque jour
De manière unitaire cela ne représente que peu de temps, mais en cumulé on arrive à presque 65 jours… une durée colossale ! Comment mettre à profit ce temps perdu ? Et bien en le mettant à profit pour améliorer la numérisation des livres par OCR (Optical Character Recognition) !
Le service CAPTCHA est alors modifié et 2 mots seront proposés :
- L’un permettra de savoir s’il s’agit d’un humain ou d’un robot (fonctionnement classique du CAPTCHA).
- L’autre sera extrait d’une numérisation d’un livre que le système OCR n’est pas parvenu à déchiffrer. Ce mot est soumis à de nombreux utilisateurs (collaboration massive ou crowdsourcing) : au bout de plusieurs réponses identiques, le mot est appris par l’algorithme d’OCR qui l’insère alors dans le texte numérisé.
Le service reCAPTCHA a été racheté par Google et son utilisation lui permet aujourd’hui de retranscrire environ 160 livres par jour.
La collaboration massive pour apprendre une langue étrangère gratuitement en traduisant le web pour d’autres…
![]()
Après avoir construit le service reCAPTCHA et lui avoir trouvé le modèle économique qui va bien, Luis von Ahn décide de s’attaquer à l’apprentissage des langues étrangères.
Le postulat de départ était simple :
- Permettre à tous d’apprendre une langue étrangère, quel que soit son niveau.
- Un service doit totalement gratuit pour l’utilisateur et sans publicités disgracieuses pour le financer.
- Utiliser la collaboration massive.
Les bases du service DUOLINGO étaient posées !

En plus du modèle de revenu par collaboration massive, Luis von Ahn va ajouter celui un peu moins connu de l’Infrastructure multiface : les cours de langues sont totalement gratuits en contrepartie d’une traduction de certains textes fournis par des tiers.
Évidemment la phase traduction ne démarre pas immédiatement, le service analyse en permanence le niveau de l’étudiant (et dans une certaine mesure son assiduité) . Lorsque celui-ci est estimé suffisant, on lui propose de poursuivre l’apprentissage sur de « vrais textes » qui seront fournis à DUOLINGO par des sociétés payant pour la traduction.
La traduction s’effectue suivant un principe comparable à celui de WIKIPEDIA : une saisie ouverte à tous les étudiants ayant le niveau suffisant, chacun peut la modifier ou la compléter. Chaque passage est ensuite noté par la communauté. Au final, le service analyse toutes les propositions pour choisir la version la plus pertinente.
Dans la vidéo ci-dessous Luis von Ahn nous explique comment à partir de cette idée d’utilisation des « petites contributions » de façon massive pour aider à la numérisation des livres, il a eu l’idée de monter un service gratuit de traduction du web de grande précision.








